





ForkとGithubの使い方を初心者なりに整理してみる
私はプログラマーではないですが、最近、業務でForkというGithubのツールを使用しています。
これが非常に便利で、プライベートの開発でも使えるのではないかと思い、備忘録として使い方を残そうと思います。
前提として、Githubを使っていることを想定していますので、そもそもGithubって何?という話にはあえて触れません。
Githubについてはウェブ上にかなり纏まった記事が沢山あります。
私のおススメはサル先生のGit入門です。
めちゃくちゃ分かり易いのでとてもお勧めです。
Github自体に疑問がある方は是非、上記のリンクも参照しながら読み進めると分かり易いかと思います。
FORKについてはいろいろ検索して調べたのですが、網羅的にクライアントツールとしてのFORKについて書いていブログが少ないと思い、この記事を書くことにしました。
私はプログラマーの背景を持たないため、Github特有の言葉でつまづきました。(Push、 Pull、 Commit、Merge、 Pull Request、 Conflict、Remote、 Repository 、Local Repository、Branch、Origin、Tracking等々) 最初はこの様々な言葉が出てくるのが中々問題でした。
この記事ではプログラムをあまり触ったことがない人でもForkについての理解を深められるようにかみ砕いて書いたつもりです。
そして、記事を読み終える頃には上記の単語の概念もある程度理解できるようになるはずだと思います。
あくまでも初心者の視点から書いておりますので、理解が浅いかもしれませんが、間違いなどありましたらご指摘いただけると幸いです。

目次
Forkってなに?(クライアントツールとして)

Forkとはまず、クライアントツールです。でも、そもそもクライアントって何?って話ですよね。
クライアントツールとは何か
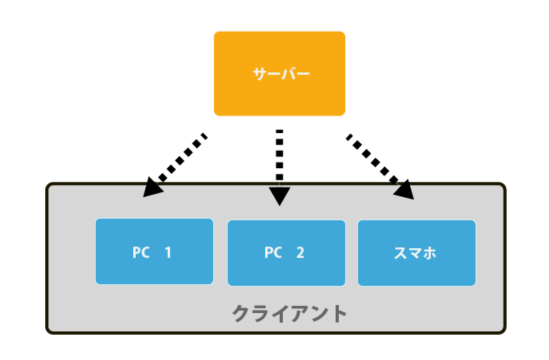
まずは、クライアントとサーバーとは何かというお話をします。
例えばグーグルメールのサービスはウェブ上のサーバーで運用されていますね。
そのおかげで、家のPCからでも、スマホからでもアクセスできます。
そのサーバーにアクセスして、繋がっている個々のPCのことをクライアントと呼びます。
よって、クライアントツールとは、サーバー側ではなくてユーザー個人側(ローカル)のコンピューターで使うツールですよということです。
Githubはウェブ上のサーバーにプログラムを保存/管理するサービスです。
それに繋がっている個人のコンピューター(クライアント)で、使うツールの1つがFORKというわけです。
FORKはなにをするためのソフトなの?
FORK(フォーク)とはもともと「分岐する」という意味です。
誤解を恐れずに言うならば、Githubのサーバー上にあるデータから、分岐したデータを作って(ブランチを切る)編集等をするためのソフトです。
そして分岐したデータ(Branch:ブランチ)に改変を加えたり、そのデータをサーバーに戻してあげたり(Merge:マージ)するのを助けるような機能が沢山ついています。
つまり、サーバーのデータを直接いじらずに、分岐したデータを作成し、それを編集してから、サーバーに戻すというのがFORKのソフトの基本的な使い方です。
FORKはどのようなときにつかわれるのか?
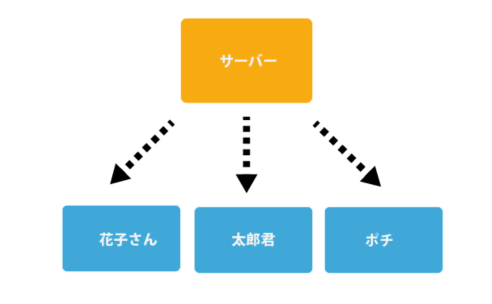
基本的には複数人での開発で使われます。
例えば、あるプロジェクトを2人で同時に並行で進める場合に、どちらの変更も安全にサーバーのデータに戻してあげることができます。
もちろん、同じファイルを改変してしまった場合には競合(Conflict:コンフリクト)が出てどちらのデータが正しいか選ぶことができます。
もしくは、どちらかのデータだけに編集内容をまとめてからサーバーにデータを戻すというようなことが必要になることもあるでしょう。
そういった、ファイルの履歴管理をしっかりできるソフトですので、複数人の開発でよく使われるようです。
Forkのダウンロードの仕方
Forkのダウンロードはこちらのリンクからできます。
リンク先でこのようなボタンが出てくるので、WindowsかMacか、自分が使っているPCの物をダウンロードします。

FORKは評価版は無料ですが、長く使うユーザーは有料版のライセンスを購入してくださいとあります。
現在私が調べた限りでは、評価版と有料版の差はなく、お金を払うかどうかはフォークを使うユーザーの良心に委ねられているようです。
FORKデベロッパーをサポートしてあげる意味で、長期で使う方は有料版を購入してあげると良いと思います。
有料版のポイントです。
- 買い切りのライセンスである(サブスクリプションではない)
- 個人で使用しても、商用利用しても良い。
- 1ユーザー当たり3つのマシンまで使用可能。
詳しくはここのリンクに詳細が書いてあります。(英語)
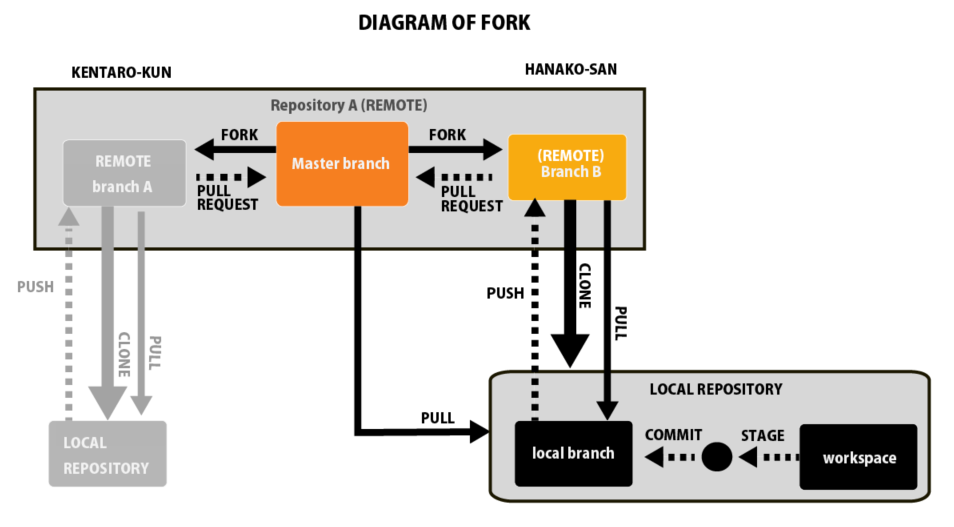
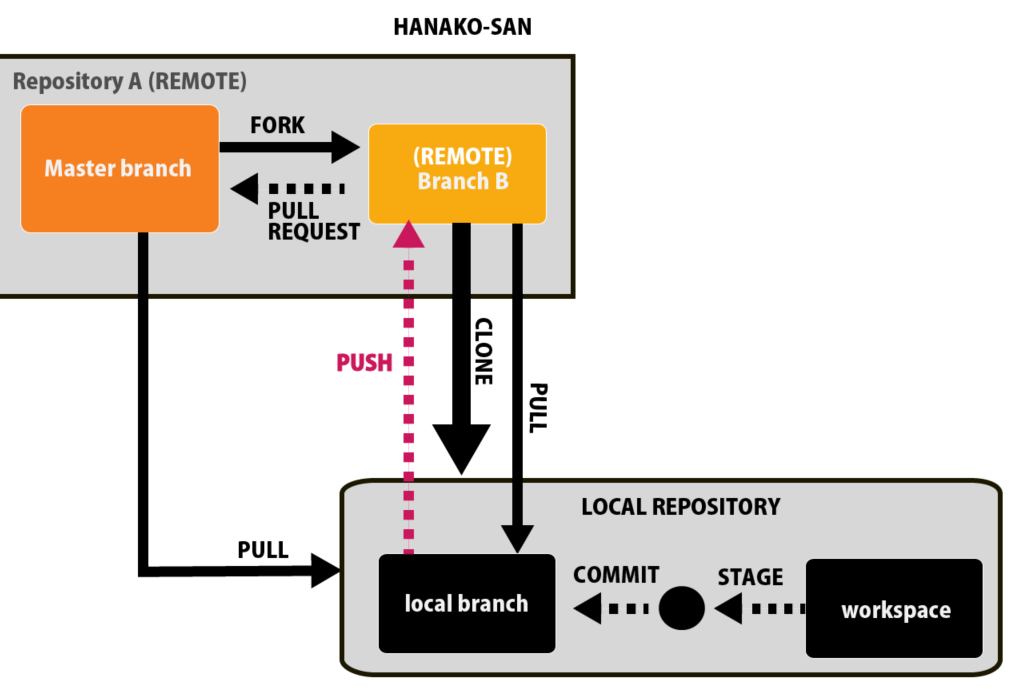
ForkとGithubの仕組みの全体像
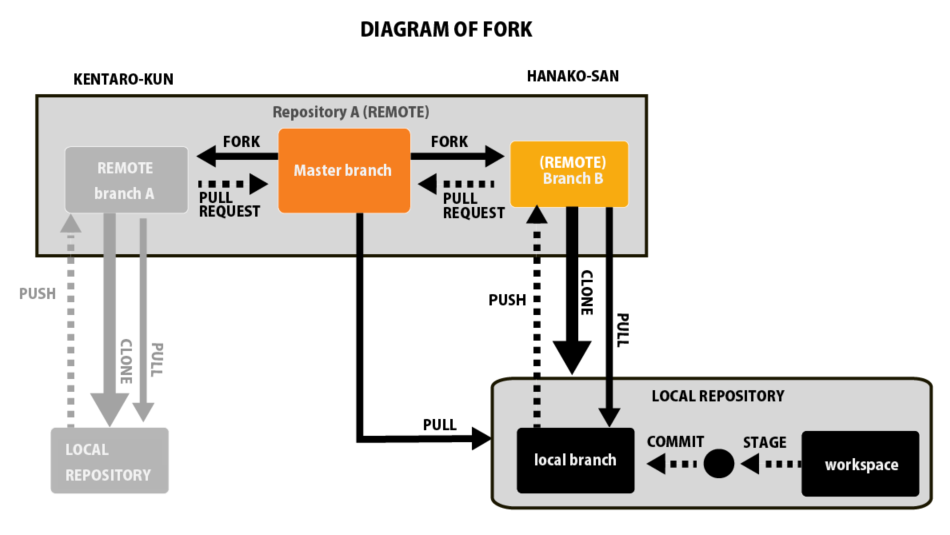
まずはFORKがどのようにファイルをコントロールしているか、全体を図で確認しましょう。
このような関係性になっています。
この時点では何のことかさっぱりだと思いますので、この図をこれから説明していきます。
まずはこの図の一番上の部分について焦点を当ててお話をします。
一番大きな枠組みはRepository:リポジトリです。
このリポジトリとは何でしょうか。これについて詳しく次の章でお話します。
ForkとGithubの仕組み:Web(リモート)編
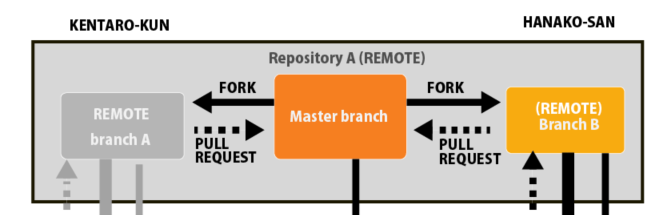
ウェブ上でのやり取りは上のような図になります。
矢印はデータの送信、受信を表しています。
それでは、これから細かく見ていきましょう。
Repository:リポジトリとは何か

まずは言葉の定義です。Repository:リポジトリという言葉があります。これはプロジェクトデータを格納している入れ物のことを言います。
例えばAというプロジェクトがあったとして、Aのプロジェクトのすべてのファイルはウェブ上のGitHubのリポジトリに格納されています。
例えば、上図に表示されているようなモデルデータやコード、設定ファイル、テクスチャなどがフォルダ分けした状態で格納されています。
このオリジナルのRepository:リポジトリはWebのGithubのサーバー上に通常は設けられており、それの(マスターブランチ)をWeb上でForkして新たなブランチを切ります。
そして、そのブランチはウェブ上にあるので、Remote Branch:リモートブランチと呼ばれたりもします。
これもまだGithubのサーバー内の話です。
要するにGithubのサーバーにはマスターブランチと、そのブランチから派生しした、個人のアカウントに紐づいているリモートブランチとの二種類が存在します。
例えば二人で開発する場合、花子さんの持っているアカウントのリモートブランチ、太郎君のアカウントのリモートブランチ、それから元のマスターブランチの3つが存在するということです。
そして、それらの個人に紐づいたブランチはマスターブランチに貢献することが前提としてあります。
Web上にあるそのプロジェクトのレポジトリのことをリモートレポジトリと呼びます。
Remote Branch:リモートブランチとは何のためにあるのか
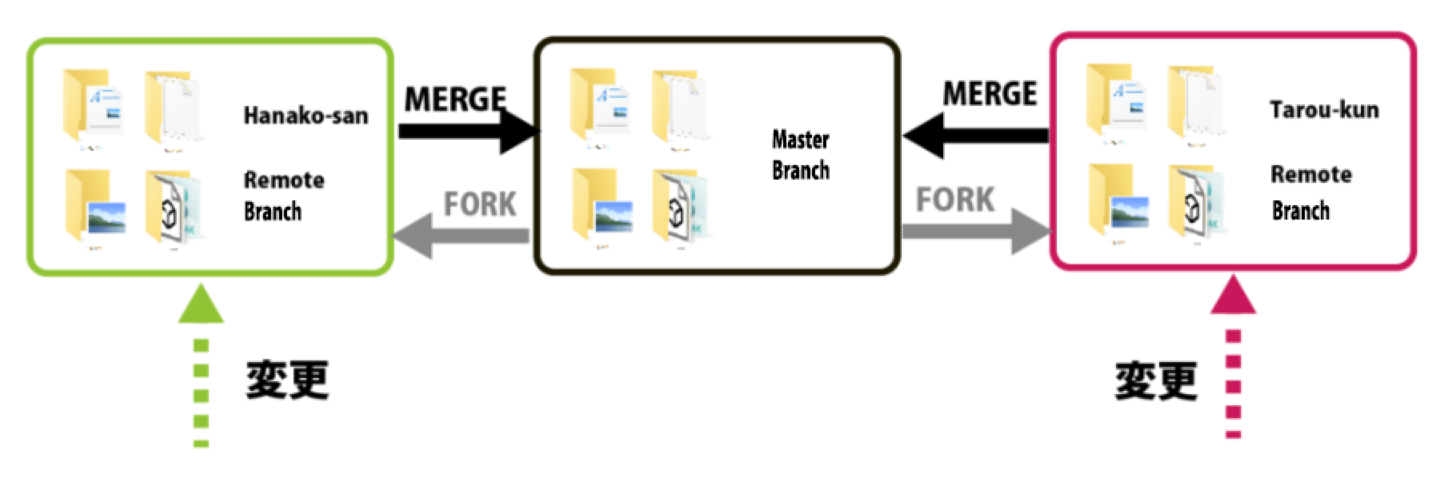
このオリジナルのリポジトリがGithub上に作成されている理由は、ソースコード管理、ファイルのバックアップ、履歴管理、共有、閲覧、変更内容の統合等ができるようにという目的等からですが、この個人のアカウントのリモートブランチを作成する意味は何かと思われるでしょう。
リモートブランチは、本流とは別に自分が改変した最新データを一時的に管理・保管しておくための場所です。
直接マスターブランチをいじってしまうと、大切な元データが失われる可能性があります。
その代わりに自分のリモートブランチにデータの変更をアップロードすることで、クッションを一つ設けてあげるというのが目的です。
それから複数人のチームで運用している場合には、その人数分の違ったバージョンのブランチが作成されます。
それをきちんと別々のブランチで管理してあげるのも一つの理由となります。
安全なデータが作成されていることが確認でき、かつ、オリジナルデータの書き換えをしたい時のみ、自分のリモートブランチの内容をオリジナルに統合(Merge;マージ)してあげるということになります。
Merge;マージ
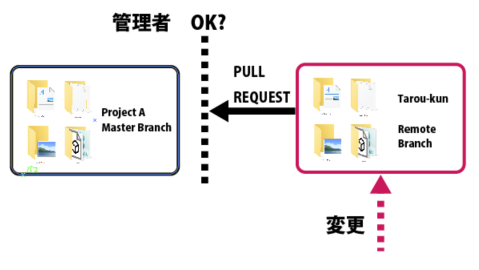
Merge:マージとはリモートブランチのデータをオリジナルのブランチに統合する作業のことを言います。
これは基本的にはPull Request:プルリクエストというのをオリジナルデータの管理者に送り、それをOKしてもらう必要があります。
マスターブランチの内容と競合(Conflict:コンフリクト)が発生せず、安全な状態のデータしか受け付けをしないことができます。
この機能によってオリジナルのマスターブランチにあるデータが守られています。
コンフリクトが発生した場合には、担当者同士がきちんと話を付けてどのデータがもっとも良いものか判断してからマージします。
ここまでが、Web(クラウド)上のお話です。
ここからは実際に自分のPC(コンピューター)上のデータと、リモートブランチのデータがどのように関係するかについてお話します。
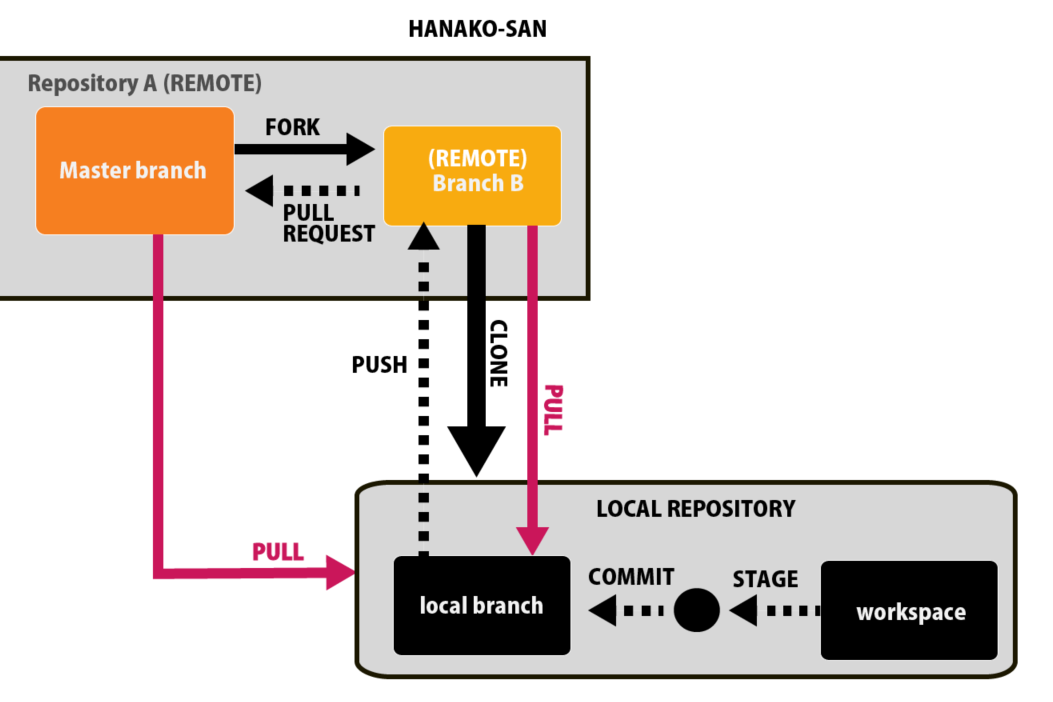
ForkとGithubの仕組み:ローカル編
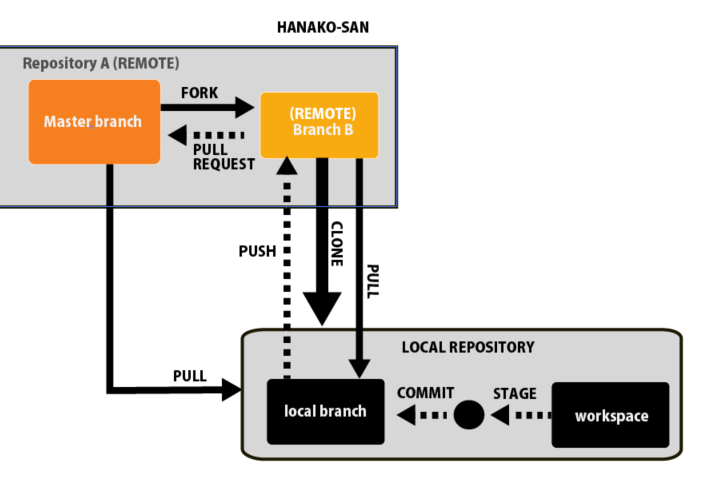
まずはFORKがどのようにローカルでファイルをコントロールしているか、全体を図で確認しましょう。
上の図ような関係性になっています。
この時点では何のことか分かりにくいと思いますので、以下では、この図をかみ砕いて説明していきます。
Clone:クローン
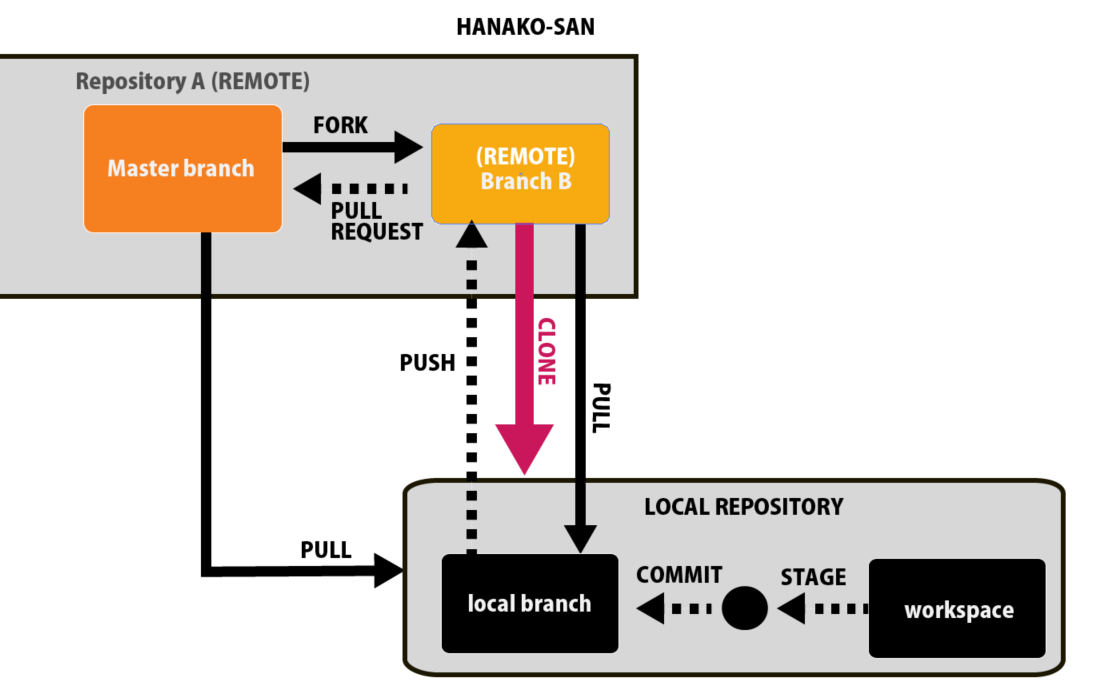
まず、ローカルのPC(個人のPC)で作業をするためには、自分のPC内にデータをコピーしてあげる必要がありますね。
これをClone:クローンといいます。
これはCloneする元がAの元データ(メインブランチ)なのか、Bの個人のリモートブランチのデータなのかの2通り存在します。
FORKしたばかりであれば、A=Bなのでどちらからクローンしても同じということになります。
自分が改変したデータを自分のPC内に引っ張ってくるためにはBのリモートブランチをクローンしますし、元データが欲しい場合にはもちろんAのオリジナルのマスターブランチからクローンします。
どちらが良いかはその時々の状況によって変わります。
どちらにしろ、ウェブ上のデータをそのまま自分のPC内に再現するのをクローンといいます。
基本的にはプロジェクトの開発を始める時にはクローンを使います。
Local Repository:ローカルレポジトリ
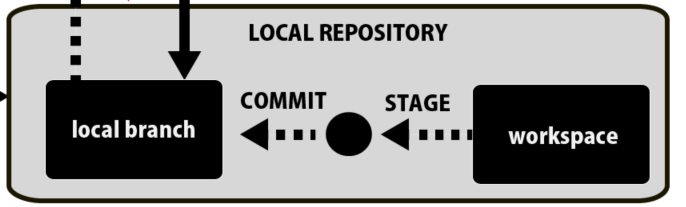
そして、このクローンされたデータが格納されている環境のことをLocal Repository:ローカルレポジトリと呼びます。
自分のPC上の自分しか見れない環境です。
ウェブ上にあるのがリモートリポジトリ、自分のPC内にあるのがローカルリポジトリです。
このローカルリポジトリ内の変更を、ウェブに反映させるには、後述のPush:プッシュを行います。
Stage:ステージ
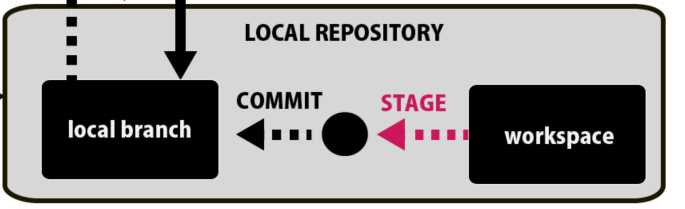
まず、自分のワークスペース内のデータに変更が加わった場合、それは自動的にFORKによって検出されFORKを開いた際にStage:ステージするかどうかの判断を迫られます。
例えばUnityを開いて変更をし、セーブしたとすると、いくつかのファイルがFORK内で変更されたよ!と通知してくれます。
そこで、ステージとは何かというと、変更を加えたいファイルのみを選択することをステージといいます。
なので、もし、誤って変更を加えてしまった場合、ステージしない(unstage)という選択ができます。
この機能によって自分の変更を加えたいファイルのみを選別することができます。
Commit:コミット
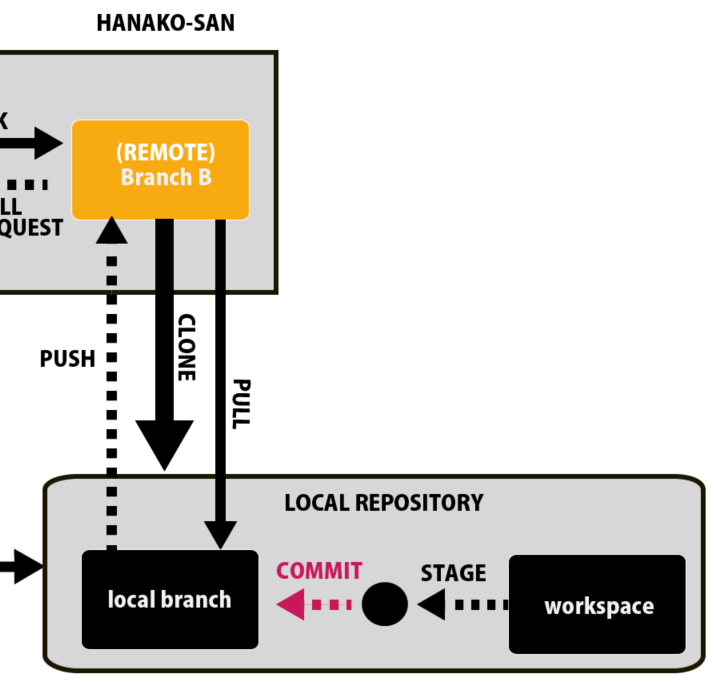
ステージによって自分が変更を加えたいファイルのみを選別できたら、それをCommit:コミットします。
これは、LocalRepository:ローカルレポジトリ内の変更を記録するという意味合いを持ちますが、新たにLocal Branch:ローカルブランチを切っていることに相当します。
これはコミットされた自分の変更を記録し、万が一その時点に戻りたい場合、そこに戻れるようなセーブポイントを作るということです。
Githubには履歴を管理する機能があり、その履歴作成がコミットすることによって記録されるということになります。
しかし、この時点ではまだ、ローカルブランチが作成されただけで、ウェブ上のリモートブランチに変更は加えられていません。
あくまでもここで作られているのはローカルブランチであって、リモートブランチ上に変更が加わっているわけではないのです。
ここが一番ややこしい所です。
(これを正しく理解するためには後述のPull:プル時の挙動を知る必要があります。)
Push:プッシュ
コミットしたローカルレポジトリ内の変更(ローカルブランチ)をリモートリポジトリ内のリモートブランチに反映することをプッシュといいます。
これで、初めてウェブ上の個人のリモートブランチに変更が加わった状態になります。
(しかし、もちろんプルリクエストが承認されるまでマスターブランチに変更は加えられません。)
Pull:プル = Fetch:フェッチ + Merge:マージ
あるウェブ上のリモートリポジトリから、データを自分のローカルリポジトリ内に反映することをPull:プルといいます。
マスターブランチからプルする場合と、自分のリモートブランチからプルする場合等、ブランチの数だけどこからプルするかの選択肢があります。
ここで注意すべきことは、コミットした記録はプルによって上書きされません。(プルしてきたデータがコミットしているデータと競合を起こさない限りはですが。)
プルとは(fetch: フェッチ)+(merge:マージ)のことです。(フェッチとはブランチの更新状態を取ってくることをいいます。ただしマージはしません。)
プルしたデータはマージされるため、コミットした変更点と両方とも合わせた状態で記録されます。
要するにコミットした変更点も生き。Pullしてきた変更点も生きというわけです。
もし、コミットしているファイルがない場合はそのままローカルリポジトリがプル元のデータによって上書きされるだけです。
もし、同じファイルを書き換えてしまっている場合は競合(Conflict:コンフリクト)が出ます。
それはどちらの変更点を優先するかを決めて競合を解消し、その内容をコミットする必要が出てきます。
どちらの変更点を優先するかは自由に変更可能です。
Pullの便利なポイント
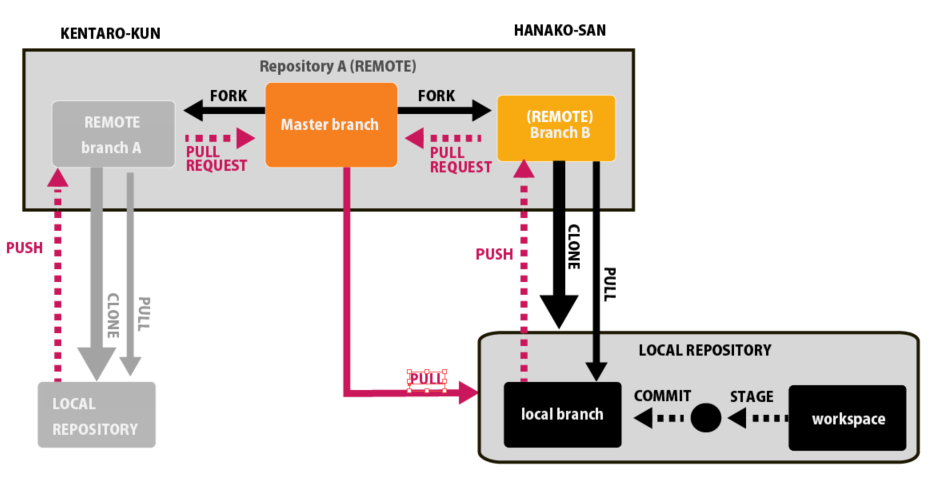
このプルが非常に便利なのは複数人でファイルを編集している場合です。
例えば、ある人(健太郎君)が凄く沢山の変更点を作成してそれを自分のリモートリポジトリにプッシュしたとします。
そしたら、一度、健太郎くんにプルリクエストを出してもらいます。
そして、そのデータが安全だということを管理者に確認してもらい、マスターブランチにマージします。
そして、そのデータをプルしてきて、自分のコミットした内容と合わせてプッシュします。
最後にプッシュしたデータをプルリクエストを出し、マスターブランチに再びマージします。
この辺のルールは開発によって違うかもしれませんので、開発の時に設定されているルールにのっとって行われるのではないと思います。
ForkとGithubの仕組み:手順編
それでは試しに、実際の開発でどのような手順で上のプロセスが行われるか見てみましょう。
ウェブ上の作業からローカルPCへのクローンまで
まずは元データの作成ですね。最初のオリジナルのレポジトリを作成します。
次に、そのマスターブランチを自分のアカウントにフォークして新たなブランチを切ります。
そして、作成したリモートブランチを自分のPC内にクローンし、リモートリポジトリを作ります。
これで開発の準備ができました。
編集作業からマージまで
ここからは編集作業に移ります。
実際のファイルを変更したら、変更内容がステージされているか確認し、必要なモノだけコミットします。
コミットが済んだら、フェッチして他の人の編集状況を確認して、編集内容が進んでいるようであれば、一度他の人のリモートリポジトリに変更をプッシュしてもらい、その内容をプルします。
そうするとプルした内容と自分のコミットした変更点が合わせて記録されるので、それをさらに自分のリモートリポジトリにプッシュします。
最後に、プルリクエストを出し、オリジナルのリポジトリに自分のリモートリポジトリ内の変更内容をマージします。
ForkとGithubの仕組み:実際のFORKでの作業画面編
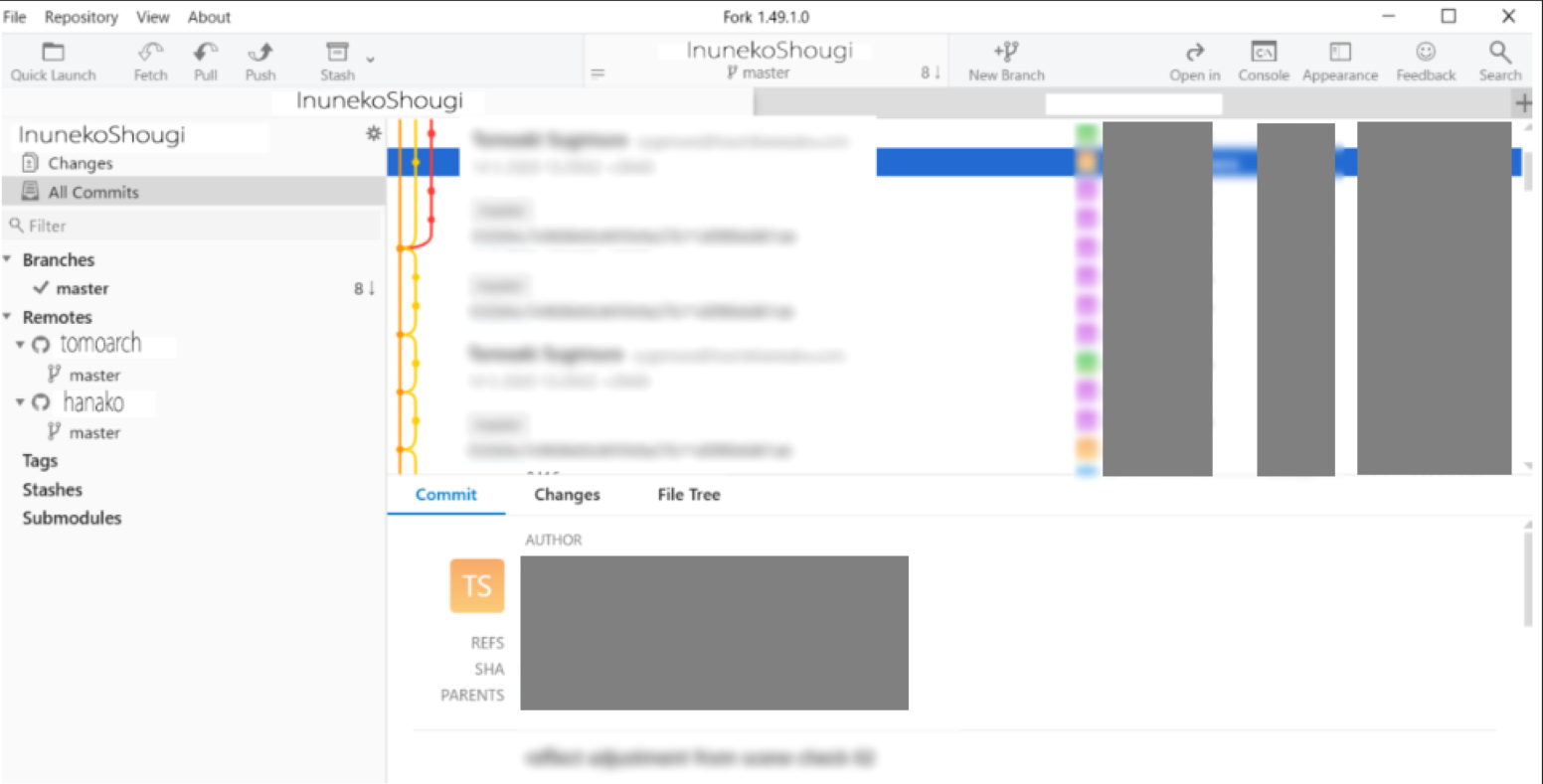
それでは実際のFORKの使い方を確認していきましょう。
(ぼかしが入っている所は、各リモートのコミットされた更新情報一覧です。)
まずは元になるデータを作成し、GITHUB上にオリジナルのレポジトリを作成します。
GITHUB上に最初のオリジナルのレポジトリを作る
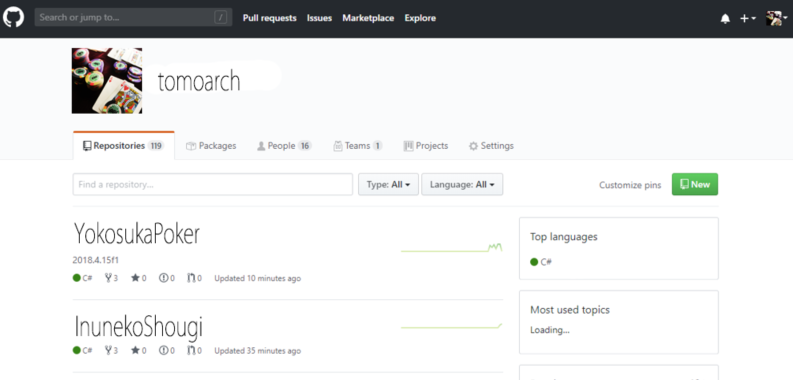
GITHUBのプロジェクト管理者のアカウントにアクセスし、新規レポジトリを作成します。右上の緑のNEWをクリックします。
Repository Nameにプロジェクト名を入れます。
Descriptionにはプロジェクトの概要や、使用しているプログラムのバージョンなどを入れます。
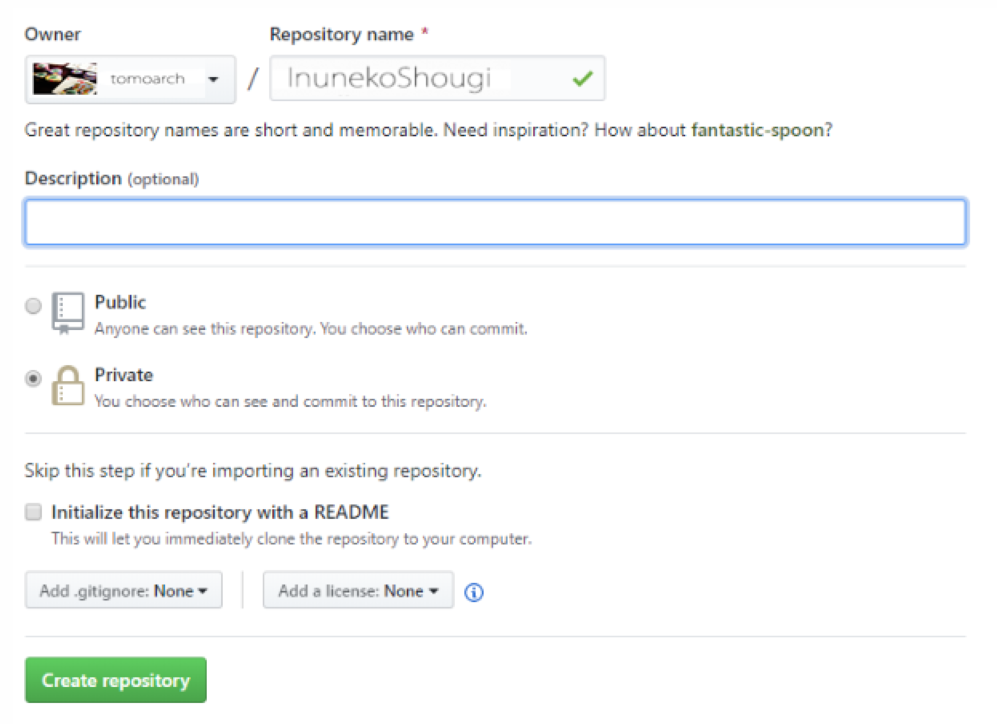
緑色のCreate repositoryを押します。
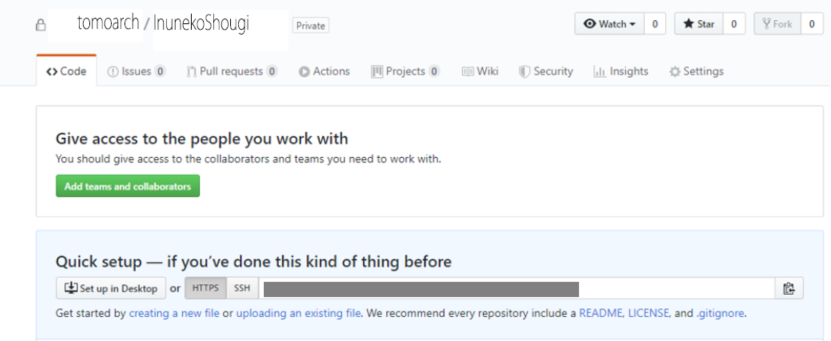
すると、灰色の部分にリンクが作成されます、これを右のボタンをクリックしてコピーします。
FORKを起動して、File>Cloneを選択します。
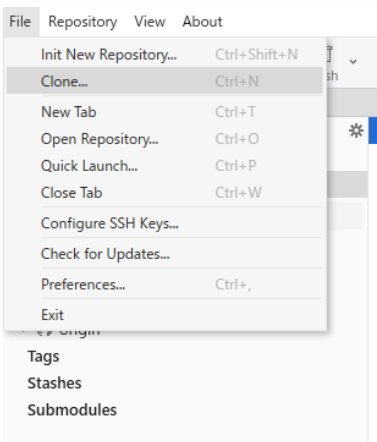
すると、自動的にコピーしているリンクがRepository Urlに入ります。
Parent FolderにはGITで使用するフォルダを選択しておきます。
そして、Nameにプロジェクト名が入るはずです。
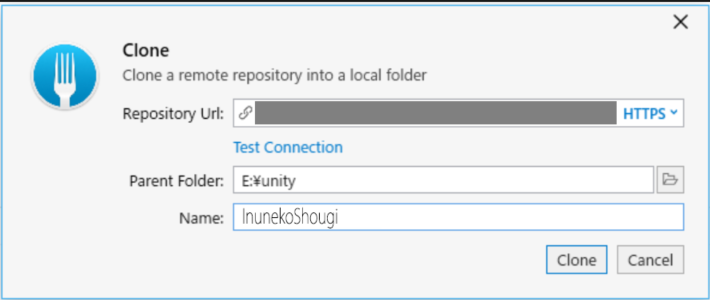
この状態で、Cloneを押します。
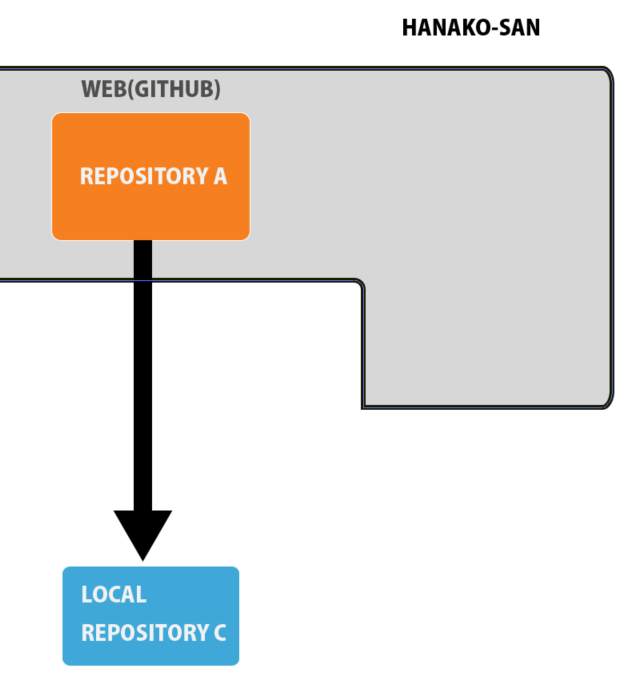
すると、ローカルレポジトリが作成されます。
上のダイアグラムでいうならば、まだリモートリポジトリが存在していないので、下のような理解になります。
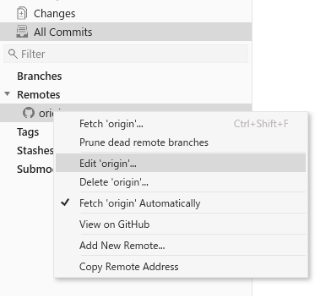
Remote>origin>Edit originで名前をtomoarchに変えます。
これはoriginという名前が分かりにくいからです。
自分のPC内にできたunity>InunekoShougiフォルダに必要なファイル等を入れます。
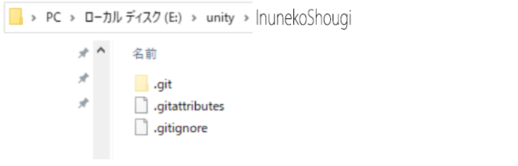
すると、FORKが変更点を自動で検出します。
Changesの横が(2)になっているのが確認できます。
それから、Unstaged Changeに二つのファイルが追加されているのが確認できます。
このファイルをStageボタンを押すことでステージし、コメントを付けてCommitボタンでコミットします。
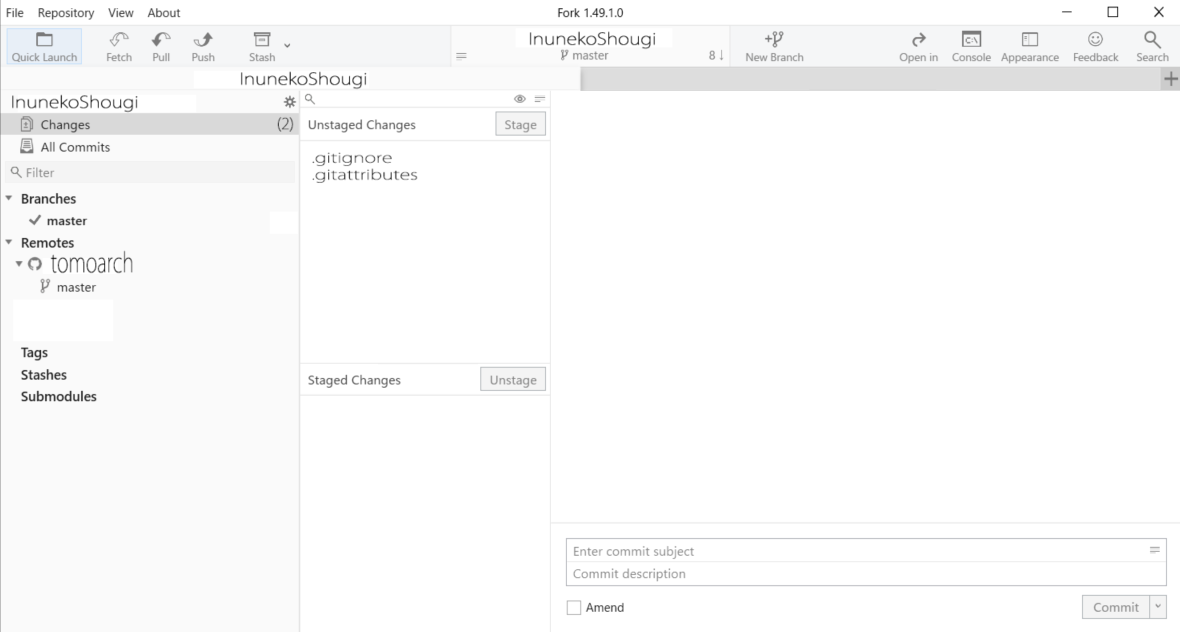
そして、コミットができたらPUSHボタンを押します。
これでオリジナルのリポジトリにデータが入りました。
Githubのサイトで確認すると下のようになっています。
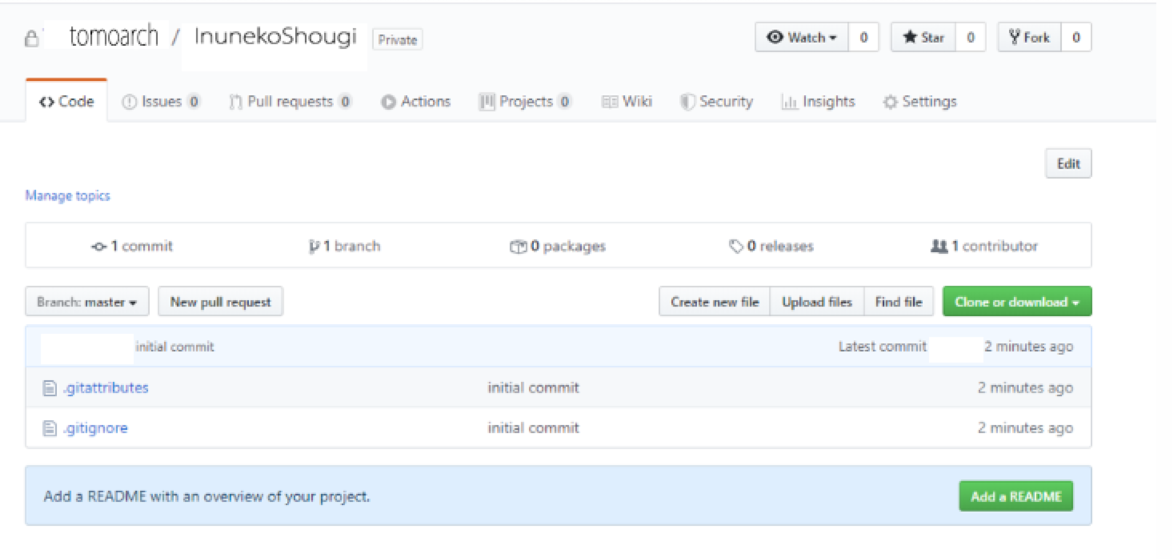
無事、二つのファイルがアップロードされたのが確認できます。
GITHUB上にリモートブランチを切る
それでは、これからリモートブランチを作成します。
例えば、花子さんのアカウントで、先ほどのオリジナルのリポジトリのページにアクセスします。
そのためには、フォークのマークがあるボタンを押します。
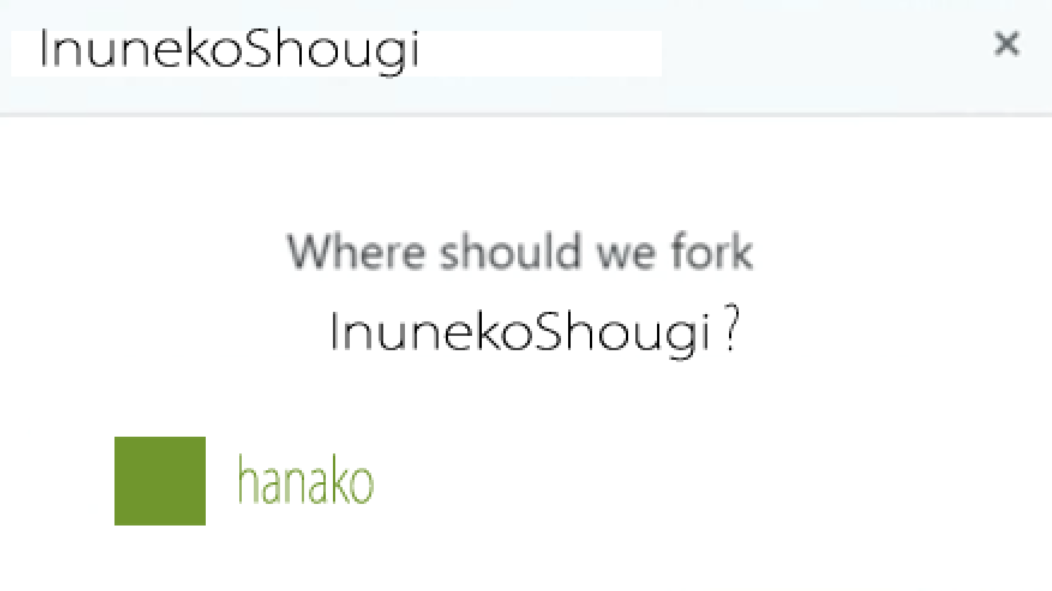
すると下のようなウインドウが出てきて、花子さんのアカウントでリモートブランチを作ることの確認ができます。
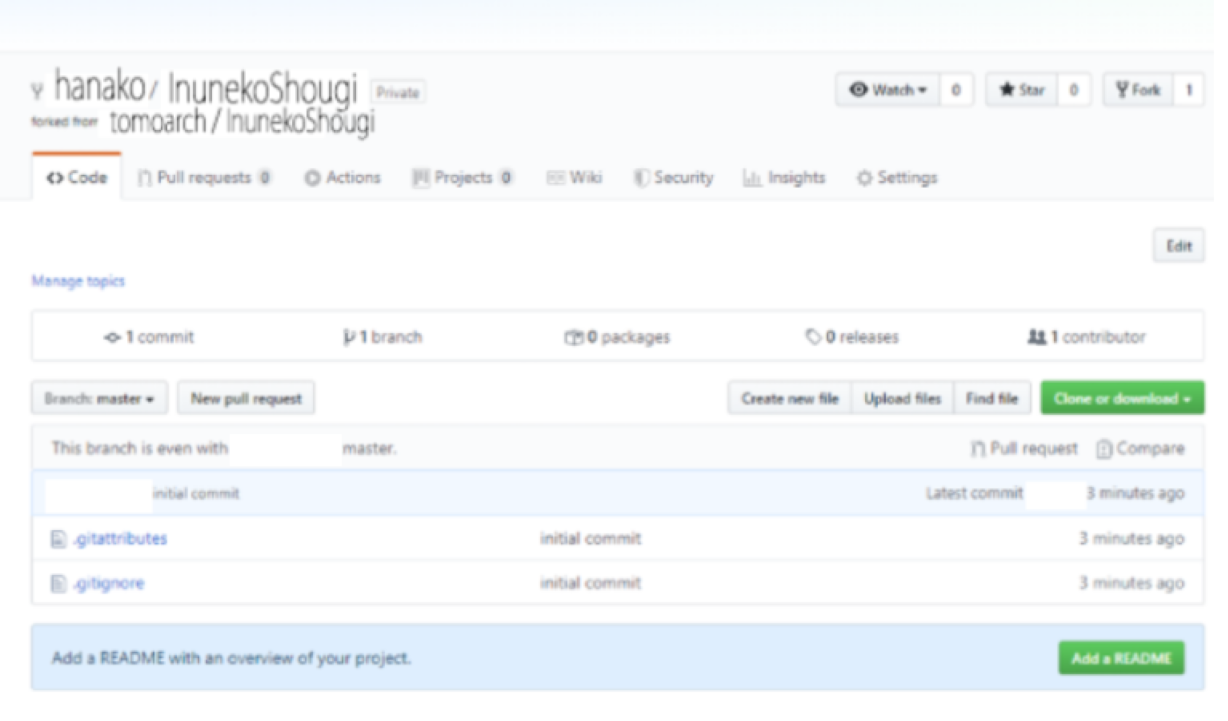
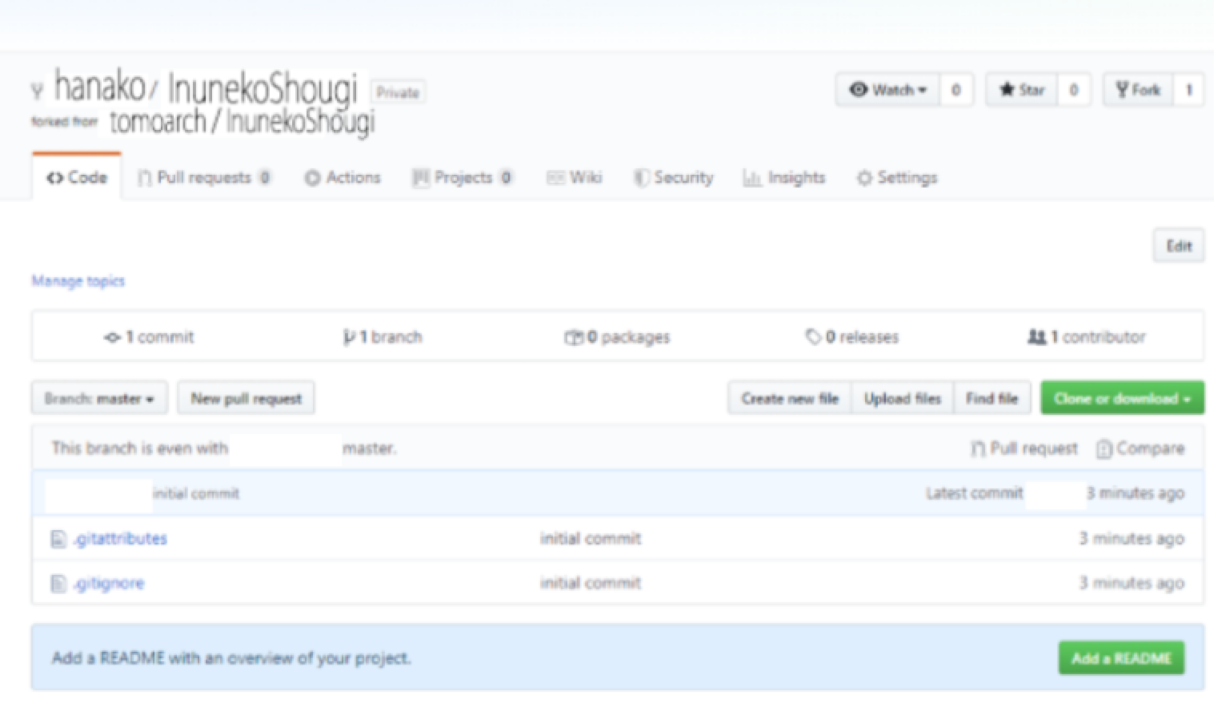
hanakoをクリックします。
すると下のような画面になります。
Tomoarch/InunekoShougiからフォークされてhanako/InunekoShougiが作成されたのが分かります。
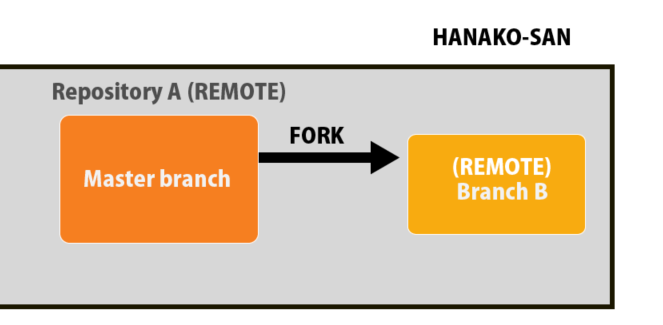
これで、フォークがされたことになります。
ダイアグラムでいうこのプロセスです。
ローカルPC上にリモートレポジトリを作る
次に、作成されたリモートブランチからクローンします。
先ほどの画面の"Clone or download" を押します。
するとリモートブランチのリンクがコピーされます。
FORKを開いて、Remote>Add New Remoteを選択します。
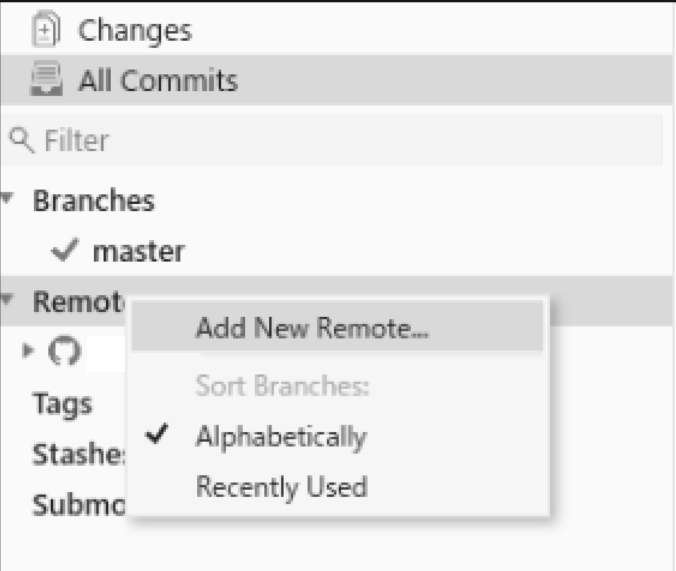
これでリモートブランチがローカルレポジトリにコピーされます。
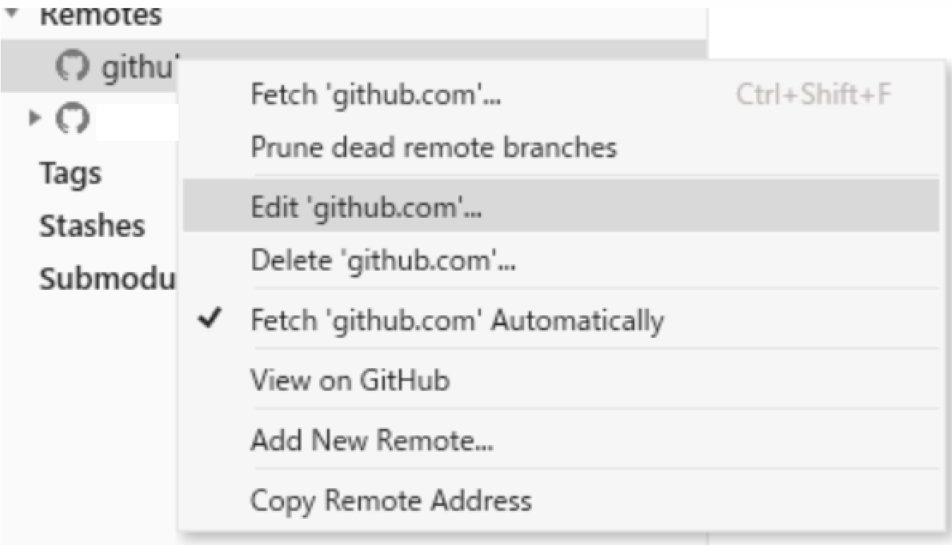
デフォルトでは名前がアドレスになっているので、名前を分かり易いようにhanakoに変えます。
Trackingといって、プッシュする先がデフォルトではtomoarchになっているので、それをhanakoにチェックします。
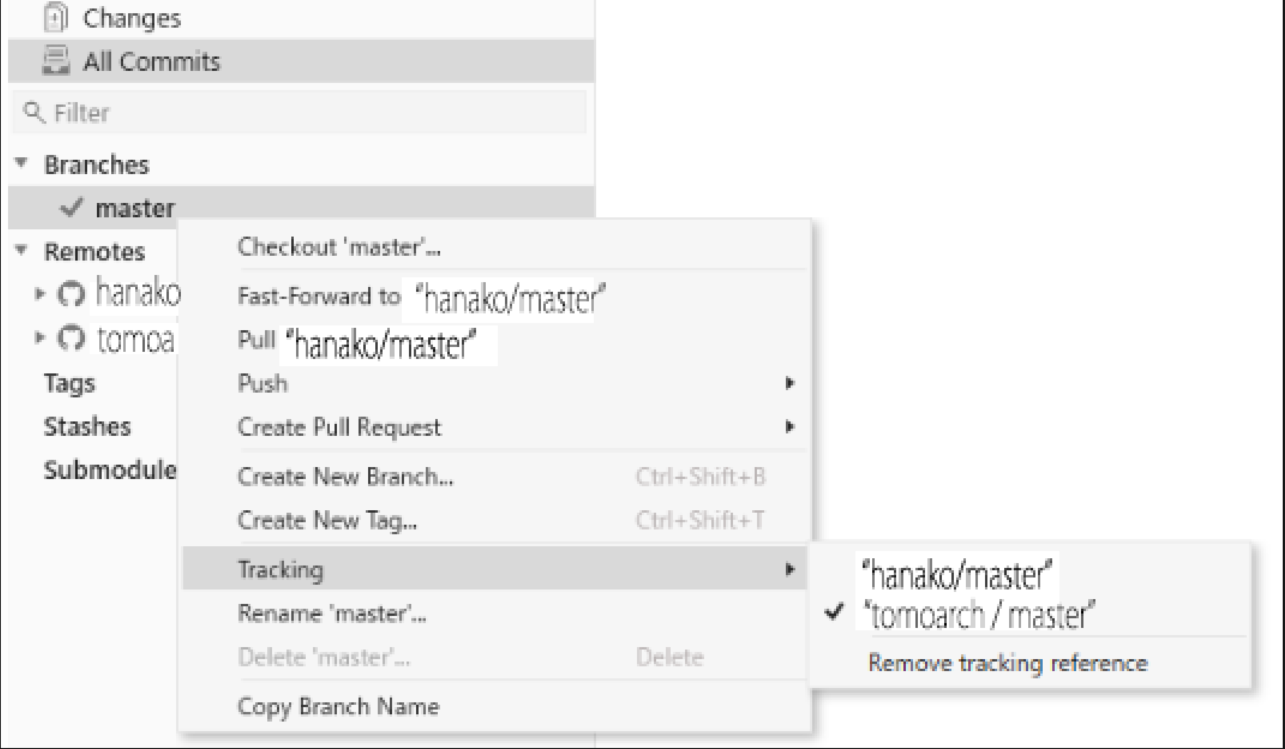
hanakoにトラッキングのチェックが入っていれば、次からプッシュする時はhanakoのリモートブランチにプッシュされます。
これでリモートレポジトリからローカルレポジトリのコピーが終わり、開発の準備ができたということになります。
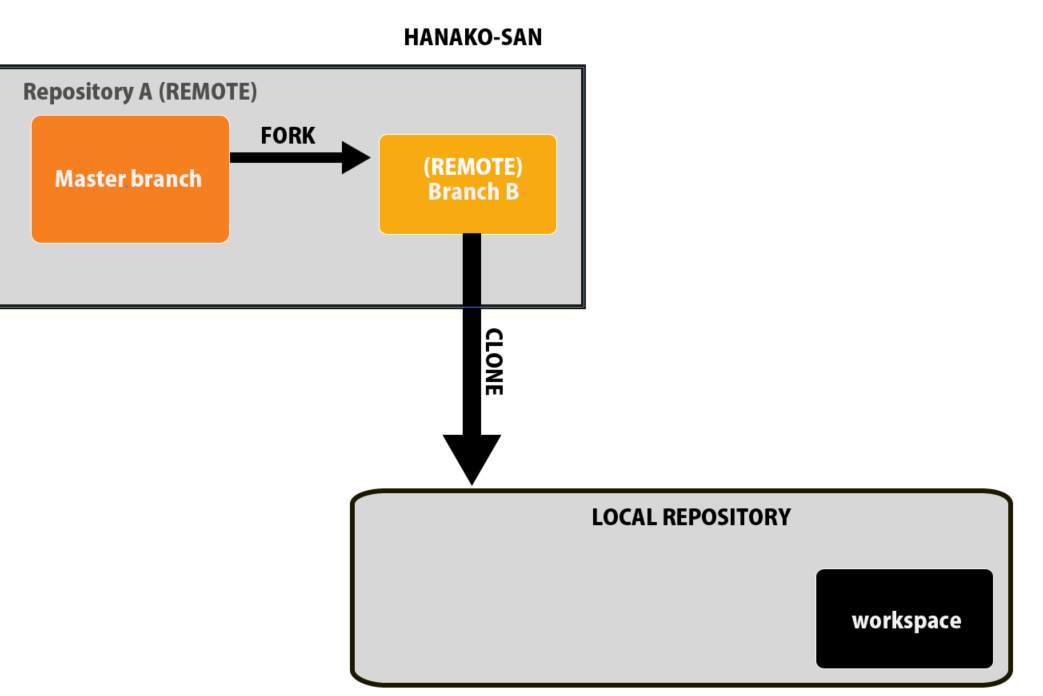
ダイアグラムで言うとここまでできたということになりますね。
トラッキング先がTomoarchになっている場合、オリジナルのマスターブランチに直接データをアップロードしようとしてしまうので要注意です。
ステージ、コミット、プル、プッシュ、マージリクエストまでの一連の流れ
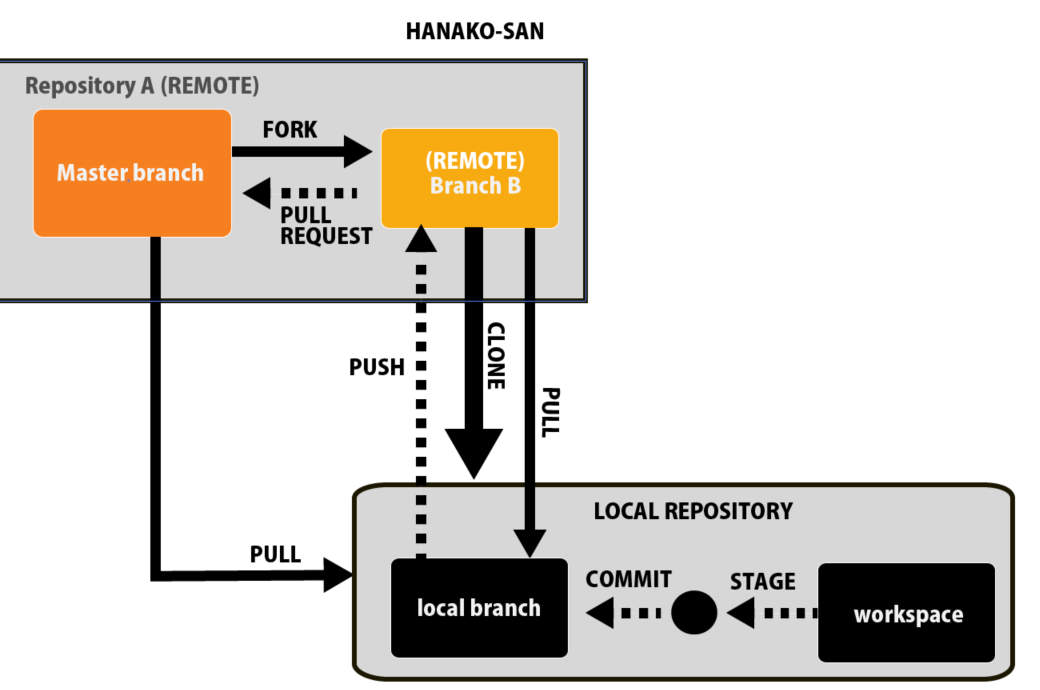
何かファイルを変更した場合、まずステージし、コミットします。
これは先ほどの2つのファイルをコミットするのと同様の手続きです。
そして、PUSHを押すことでトラッキングが入っているリモートの方にプッシュされます。
PULLする場合は、どちらのリモートからプルするかを聞かれるので、正しい方を選択してあげます。
すると、コミットしたファイルとプルされた情報が合わさり、プッシュするとリモートブランチにアップされます。
Fetchとは何か
さて、最後にFetchとは何でしたでしょうか。
これは、リモートブランチの誰かが更新をして、FORKの情報が古くなった場合に新しい更新情報を取りに行くことをいいます。
データを取ってくるだけでマージはしません。そこがプルとの違いです。
なので、何か更新があったかどうか確かめるためにはFetchボタンを押す必要があります。
まとめ

記事を書きながらいろいろな方からご指摘を頂き、何度も練り直しました。
これからもこの記事は学びがあるたびに更新していこうと思います。
まだまだ、分からないことが沢山ありますが、何かご意見などありましたら是非ともお寄せください。
FORKについて理解が進むと開発が楽しみになりますね。
まだわかっていない機能等もありますので、これからも学びがあるたびに記事が更新されていくことになります。
また、何か間違いなどありましたら、コメントにてご指摘頂けますと幸いです。
今回はFORKについての備忘録でした。
最後まで読んでいただきありがとうございます。
今後ともどうぞよろしくお願いいたします。